
# End-to-End Driving Via Conditional Imitation Learning
## Resource
- Source Code: https://github.com/merantix/imitation-learning
- Source Code: https://github.com/carla-simulator/imitation-learning
- [Journey from academic paper to industry usage](https://medium.com/merantix/journey-from-academic-paper-to-industry-usage-cf57fe598f31)
## Problem:
However, driving policies trained via imitation learning cannot be controlled at test time.
A vehicle trained end-to-end to imitate an expert cannot be guided to take a specific turn at an up- coming intersection. This limits the utility of such systems.
## Propose
We propose to condition imitation learning on high-level command input. At test time, the learned driving policy functions as a chauffeur that handles sensorimotor coordination but continues to respond to navigational commands.
学习人类驾驶行为后的深度神经网络已经具备车道线跟随和避障功能。但是在实际测试时,这种经过模仿学习的神经网络所做出的的驾驶策略是不受控制的。比如,一辆模仿人类驾驶行为的端到端控制的无人车是无法被控制在即将到来的路口完成特定的转弯行为。这就降低了这种端到端方法的普遍适用性。我们提出了一种在高级指令约束下进行驾驶行为模仿学习的端到端的神经网络。这个经过训练的网络可以对无人车进行运动控制,并且能同时响应拐弯、直行等高级别的导航指令。我们在不同的基于视觉的驾驶行为模仿学习架构上加入高级指令约束,分别在城市三维模拟环境和1:5缩比车的真实环境进行实验,实验结果表明两种情况下该方法都可以实现对无人车的控制,并响应高级指令。[^paopao]
提出有高级指令约束的驾驶行为模仿学习方法,可以把无人车运动控制(方向盘角、加速度)和高级指令(直行、拐弯、车道保持)结合起来,避免了现有图像到控制的端到端的方法在交叉路口决策时的模糊性。[^paopao]
## Conditional imitation learning

The standard imitation learning objective
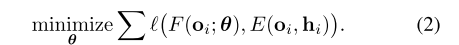
- F: Controller
- h: latent state
- c=c(h): an additional command input
Training Dataset
$$D = \{(o_i, c_i, a_i)}^N_{i=1})$$
Architecture
Fig.3
$$j = J(i,m,c) = (I(i), M(m), C(c))$$
## References
Codevilla, F., Miiller, M., Lopez, A., Koltun, V., & Dosovitskiy, A. (2018). End-to-End Driving Via Conditional Imitation Learning. Proceedings - IEEE International Conference on Robotics and Automation, 4693–4700. https://doi.org/10.1109/ICRA.2018.8460487





No comments