
 **Abstract**
They present DynaSLAM, a visual SLAM system that, building on **ORB-SLAM2**, adds the capabilities of **dynamic object detection and background inpainting**. DynaSLAM is **robust in dynamic scenarios** for monocular, stereo and RGB-D configurations. They are capable of detecting the moving objects either by **multi-view geometry**, **deep learning** or both. Having a **static map** of the scene **allows inpainting the frame background** that has been **occluded** by such dynamic objects.
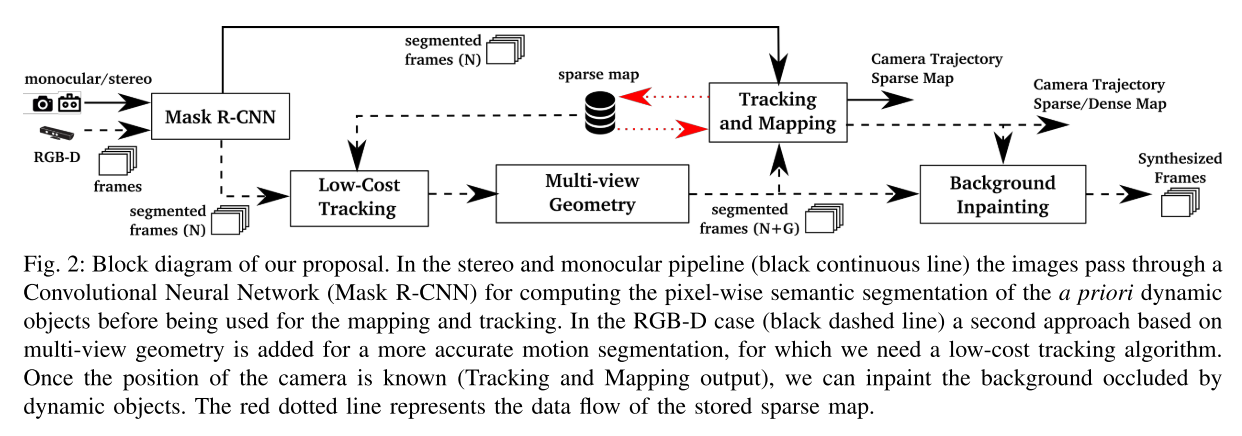
**Segmentation of Potentially Dynamic Content using a CNN**
The input of Mask R-CNN is the **RGB** original image. The idea is to segment those classes that are **potentially dynamic or movable** (person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra and giraffe). If other classes were needed, the network, trained on MS COCO, could be fine-tuned with new training data.
**Low-Cost Tracking**
After the **potentially dynamic content** has been segmented, the pose of the camera is tracked using the **static part of the image**. The tracking implemented at this stage of the algorithm is a simpler and therefore **computationally lighter version of the one in ORB-SLAM2**. It projects the map features in the image frame, searches for the correspondences in the **static areas** of the image, and **minimizes the reprojection erro**r to optimize the camera pose.
**Segmentation of Dynamic Content using Mask R-CNN and Multi-view Geometry**

By using Mask R-CNN, most of the dynamic objects can be segmented and not used for tracking and mapping. **However**, there are objects that cannot be detected by this approach because they are **not a priori dynamic,** **but movable**. Examples of the latest are a book carried by someone, a chair that someone is moving, or even furniture changes in long-term mapping.
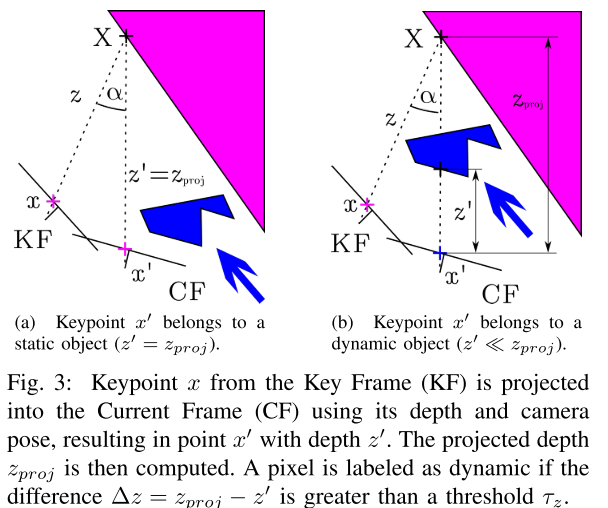
we know which keypoints belong to dynamic objects, and which ones do not. To classify all the pixels belonging to dynamic objects, we grow the region in the depth image around the dynamic pixels.
**Tracking and Mapping**
The input to this stage of the system contains the **RGB** and **depth images**, as well as their **segmentation mask**. We extract ORB features in the image segments classified as **static**. As the **segment contours** are high-gradient areas, the keypoints falling in this intersection have to be removed.
**Background Inpainting**
For every removed dynamic object, we aim at inpainting the occluded background with static information from previous views, so that we can synthesize a realistic image without moving content.

**EXPERIMENTAL RESULTS**
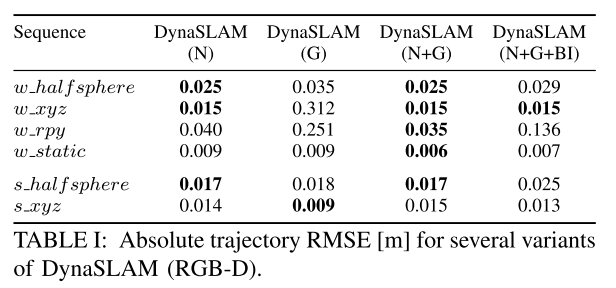
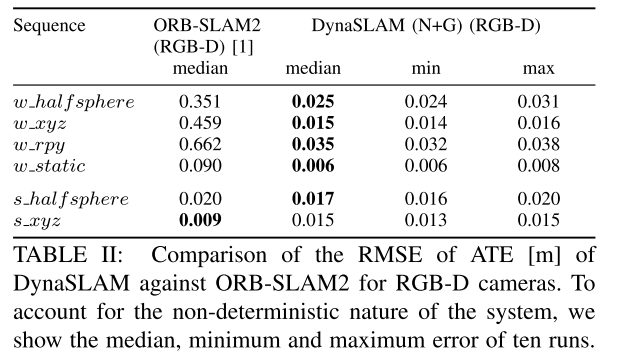
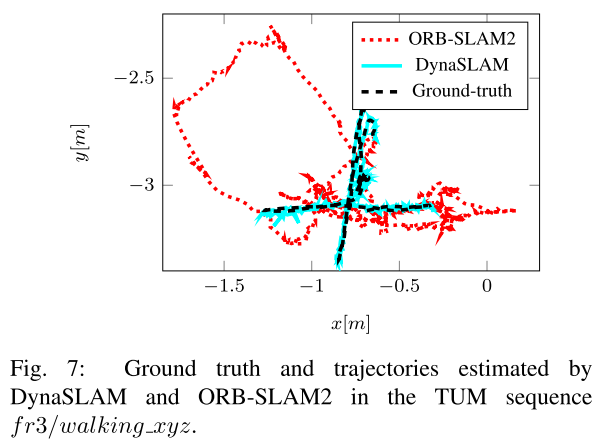
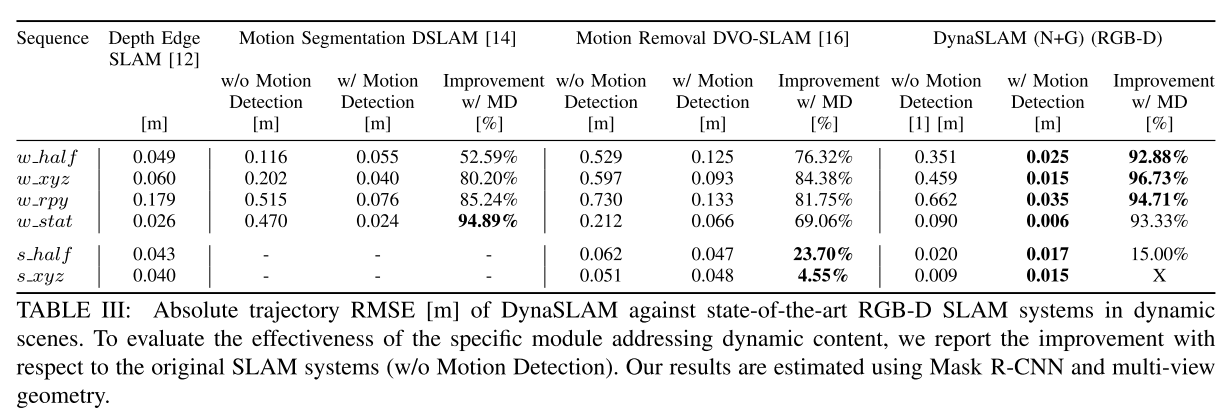
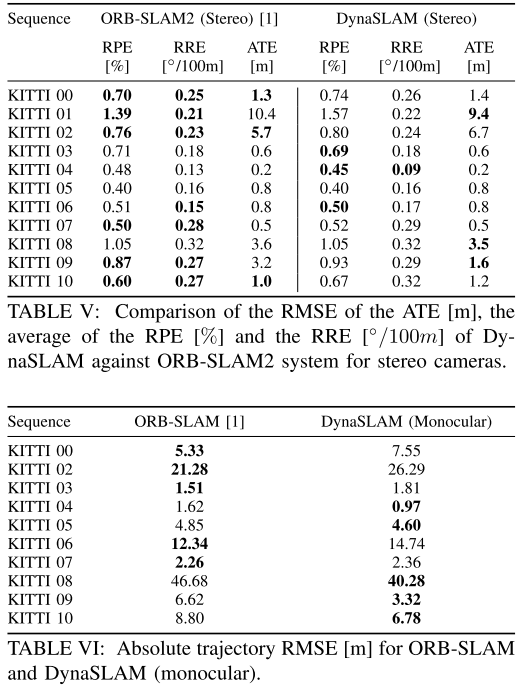
**Timing Analysis**
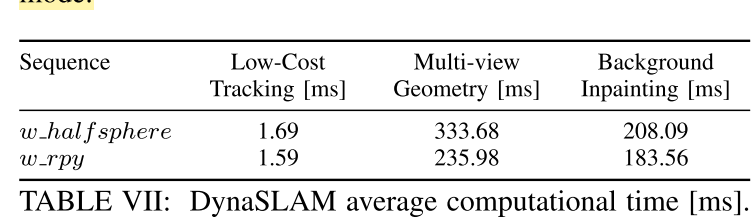
**CONCLUSIONS**
Our system accurately tracks the camera and creates a static and therefore reusable map of the scene.In the RGB-D case, DynaSLAM is capable of obtaining the synthetic RGB frames with no dynamic content and with the occluded background inpainted, as well as their corresponding synthesized depth frames, which might be together very useful for virtual reality applications.
# Reference
Bescos, B., Facil, J. M., Civera, J., & Neira, J. (2018). DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robotics and Automation Letters, 3(4), 4076–4083. https://doi.org/10.1109/LRA.2018.2860039
**Abstract**
They present DynaSLAM, a visual SLAM system that, building on **ORB-SLAM2**, adds the capabilities of **dynamic object detection and background inpainting**. DynaSLAM is **robust in dynamic scenarios** for monocular, stereo and RGB-D configurations. They are capable of detecting the moving objects either by **multi-view geometry**, **deep learning** or both. Having a **static map** of the scene **allows inpainting the frame background** that has been **occluded** by such dynamic objects.

**Segmentation of Potentially Dynamic Content using a CNN**
The input of Mask R-CNN is the **RGB** original image. The idea is to segment those classes that are **potentially dynamic or movable** (person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra and giraffe). If other classes were needed, the network, trained on MS COCO, could be fine-tuned with new training data.
**Low-Cost Tracking**
After the **potentially dynamic content** has been segmented, the pose of the camera is tracked using the **static part of the image**. The tracking implemented at this stage of the algorithm is a simpler and therefore **computationally lighter version of the one in ORB-SLAM2**. It projects the map features in the image frame, searches for the correspondences in the **static areas** of the image, and **minimizes the reprojection erro**r to optimize the camera pose.
**Segmentation of Dynamic Content using Mask R-CNN and Multi-view Geometry**

By using Mask R-CNN, most of the dynamic objects can be segmented and not used for tracking and mapping. **However**, there are objects that cannot be detected by this approach because they are **not a priori dynamic,** **but movable**. Examples of the latest are a book carried by someone, a chair that someone is moving, or even furniture changes in long-term mapping.

we know which keypoints belong to dynamic objects, and which ones do not. To classify all the pixels belonging to dynamic objects, we grow the region in the depth image around the dynamic pixels.
**Tracking and Mapping**
The input to this stage of the system contains the **RGB** and **depth images**, as well as their **segmentation mask**. We extract ORB features in the image segments classified as **static**. As the **segment contours** are high-gradient areas, the keypoints falling in this intersection have to be removed.
**Background Inpainting**
For every removed dynamic object, we aim at inpainting the occluded background with static information from previous views, so that we can synthesize a realistic image without moving content.

**EXPERIMENTAL RESULTS**





**Timing Analysis**

**CONCLUSIONS**
Our system accurately tracks the camera and creates a static and therefore reusable map of the scene.In the RGB-D case, DynaSLAM is capable of obtaining the synthetic RGB frames with no dynamic content and with the occluded background inpainted, as well as their corresponding synthesized depth frames, which might be together very useful for virtual reality applications.
# Reference
Bescos, B., Facil, J. M., Civera, J., & Neira, J. (2018). DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robotics and Automation Letters, 3(4), 4076–4083. https://doi.org/10.1109/LRA.2018.2860039
DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes [Reading Seminar]
[toc]
# 2018-DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
**Problem solved: scene rigidity assumption**
The **assumption of scene rigidity** is typical in SLAM algorithms. Such a strong assumption **limits** the use of most visual SLAM systems in **populated real-world environments**, which are the target of several relevant applications like service robotics or autonomous vehicles.
**Abstract**
They present DynaSLAM, a visual SLAM system that, building on **ORB-SLAM2**, adds the capabilities of **dynamic object detection and background inpainting**. DynaSLAM is **robust in dynamic scenarios** for monocular, stereo and RGB-D configurations. They are capable of detecting the moving objects either by **multi-view geometry**, **deep learning** or both. Having a **static map** of the scene **allows inpainting the frame background** that has been **occluded** by such dynamic objects.

**Segmentation of Potentially Dynamic Content using a CNN**
The input of Mask R-CNN is the **RGB** original image. The idea is to segment those classes that are **potentially dynamic or movable** (person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra and giraffe). If other classes were needed, the network, trained on MS COCO, could be fine-tuned with new training data.
**Low-Cost Tracking**
After the **potentially dynamic content** has been segmented, the pose of the camera is tracked using the **static part of the image**. The tracking implemented at this stage of the algorithm is a simpler and therefore **computationally lighter version of the one in ORB-SLAM2**. It projects the map features in the image frame, searches for the correspondences in the **static areas** of the image, and **minimizes the reprojection erro**r to optimize the camera pose.
**Segmentation of Dynamic Content using Mask R-CNN and Multi-view Geometry**

By using Mask R-CNN, most of the dynamic objects can be segmented and not used for tracking and mapping. **However**, there are objects that cannot be detected by this approach because they are **not a priori dynamic,** **but movable**. Examples of the latest are a book carried by someone, a chair that someone is moving, or even furniture changes in long-term mapping.

we know which keypoints belong to dynamic objects, and which ones do not. To classify all the pixels belonging to dynamic objects, we grow the region in the depth image around the dynamic pixels.
**Tracking and Mapping**
The input to this stage of the system contains the **RGB** and **depth images**, as well as their **segmentation mask**. We extract ORB features in the image segments classified as **static**. As the **segment contours** are high-gradient areas, the keypoints falling in this intersection have to be removed.
**Background Inpainting**
For every removed dynamic object, we aim at inpainting the occluded background with static information from previous views, so that we can synthesize a realistic image without moving content.

**EXPERIMENTAL RESULTS**





**Timing Analysis**

**CONCLUSIONS**
Our system accurately tracks the camera and creates a static and therefore reusable map of the scene.In the RGB-D case, DynaSLAM is capable of obtaining the synthetic RGB frames with no dynamic content and with the occluded background inpainted, as well as their corresponding synthesized depth frames, which might be together very useful for virtual reality applications.
# Reference
Bescos, B., Facil, J. M., Civera, J., & Neira, J. (2018). DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robotics and Automation Letters, 3(4), 4076–4083. https://doi.org/10.1109/LRA.2018.2860039
**Abstract**
They present DynaSLAM, a visual SLAM system that, building on **ORB-SLAM2**, adds the capabilities of **dynamic object detection and background inpainting**. DynaSLAM is **robust in dynamic scenarios** for monocular, stereo and RGB-D configurations. They are capable of detecting the moving objects either by **multi-view geometry**, **deep learning** or both. Having a **static map** of the scene **allows inpainting the frame background** that has been **occluded** by such dynamic objects.

**Segmentation of Potentially Dynamic Content using a CNN**
The input of Mask R-CNN is the **RGB** original image. The idea is to segment those classes that are **potentially dynamic or movable** (person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra and giraffe). If other classes were needed, the network, trained on MS COCO, could be fine-tuned with new training data.
**Low-Cost Tracking**
After the **potentially dynamic content** has been segmented, the pose of the camera is tracked using the **static part of the image**. The tracking implemented at this stage of the algorithm is a simpler and therefore **computationally lighter version of the one in ORB-SLAM2**. It projects the map features in the image frame, searches for the correspondences in the **static areas** of the image, and **minimizes the reprojection erro**r to optimize the camera pose.
**Segmentation of Dynamic Content using Mask R-CNN and Multi-view Geometry**

By using Mask R-CNN, most of the dynamic objects can be segmented and not used for tracking and mapping. **However**, there are objects that cannot be detected by this approach because they are **not a priori dynamic,** **but movable**. Examples of the latest are a book carried by someone, a chair that someone is moving, or even furniture changes in long-term mapping.

we know which keypoints belong to dynamic objects, and which ones do not. To classify all the pixels belonging to dynamic objects, we grow the region in the depth image around the dynamic pixels.
**Tracking and Mapping**
The input to this stage of the system contains the **RGB** and **depth images**, as well as their **segmentation mask**. We extract ORB features in the image segments classified as **static**. As the **segment contours** are high-gradient areas, the keypoints falling in this intersection have to be removed.
**Background Inpainting**
For every removed dynamic object, we aim at inpainting the occluded background with static information from previous views, so that we can synthesize a realistic image without moving content.

**EXPERIMENTAL RESULTS**





**Timing Analysis**

**CONCLUSIONS**
Our system accurately tracks the camera and creates a static and therefore reusable map of the scene.In the RGB-D case, DynaSLAM is capable of obtaining the synthetic RGB frames with no dynamic content and with the occluded background inpainted, as well as their corresponding synthesized depth frames, which might be together very useful for virtual reality applications.
# Reference
Bescos, B., Facil, J. M., Civera, J., & Neira, J. (2018). DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robotics and Automation Letters, 3(4), 4076–4083. https://doi.org/10.1109/LRA.2018.2860039




No comments